RAG(검색 증강 생성) - 우리가 이미 쓰던 그 기술
10분 만에 이해하는 RAG: 우리가 이미 쓰던 그 기술
1. 프롤로그: 우리는 이미 RAG를 쓰고 있습니다
최근 AI 트렌드에서 가장 핫한 단어인 RAG(Retrieval-Augmented Generation). 이름만 들으면 굉장히 복잡한 마법 같지만, 사실 개발자인 우리는 이미 매일 이 기술을 수동으로 쓰고 있습니다.
🤔 혹시 이런 적 없으신가요?
- 상황 1: 클로드(Claude)에게 코드를 짜달라고 할 때, 우리 팀의 코딩 컨벤션이 적힌
skill.md파일을 쓱 던져주며 “이 규칙 맞춰서 짜줘”라고 한다. - 상황 2: ChatGPT의 나만의 챗봇(Custom GPTs)이나 Gemini의 젬(Gems)을 만들 때, 회사의
취업규칙.pdf를 업로드해 두고 “내 연차 며칠 남아?”라고 묻는다.
네, 맞습니다! AI에게 내가 가진 외부 지식(파일)을 던져주고 대답하게 만드는 것. 이것이 바로 RAG의 본질입니다.
2. 수동 RAG vs 자동화된 RAG 시스템
Claude에 skill.md를 던져주고 Gemini에 Gem을 사용하는 건 ‘수동 RAG’입니다. 하지만 우리 DEKK 서비스에는 수만 개의 상품 카드(card.md가 1만 개 있다고 상상해 보세요)가 있습니다. 유저가 질문할 때마다 1만 개의 파일을 AI 입력창에 다 때려 넣을 수는 없겠죠? (비용도, 용량도 초과됩니다.)
그래서 우리 서버(Spring Boot) 뒷단에 “수많은 데이터 중 지금 질문에 딱 필요한 데이터만 시스템이 알아서 찾아내어 AI에게 몰래 쥐여주는 자동화 파이프라인” 을 구축해야 합니다. 이것이 진짜 RAG 시스템입니다.
3. RAG를 위한 필수 지식: 벡터화(Vectorization)와 임베딩(Embedding)
RAG 시스템이 수만 개의 데이터 중 ‘딱 필요한 것’만 찾으려면, 먼저 텍스트를 컴퓨터가 이해할 수 있게 바꿔야 합니다. 이 핵심 과정이 바로 벡터화와 임베딩입니다.
텍스트를 숫자의 배열로! (벡터화)
컴퓨터는 ‘듬직한 체형’이라는 글자를 그대로 이해하지 못합니다. 대신 이 단어가 가진 의미(특징)들을 수십, 수백 개의 숫자로 쪼개서 배열로 만듭니다. 마치 우리가 옷의 색상을 컴퓨터에 입력할 때 ‘빨간색’이라고 쓰는 대신 [R: 255, G: 0, B: 0]이라는 숫자로 표현하듯, 문장의 뉘앙스를 [체격크기: 0.9, 어깨너비: 0.8, 마름: 0.1 ...]처럼 수치화하는 것이죠. 이렇게 텍스트를 숫자의 묶음으로 바꾸는 과정을 벡터화(Vectorization) 라고 부릅니다.
숫자를 공간의 좌표로! (임베딩)
이렇게 만들어진 숫자의 배열(벡터)을 거대한 다차원 공간에 점(좌표)으로 찍어내는 것을 임베딩(Embedding) 이라고 합니다.
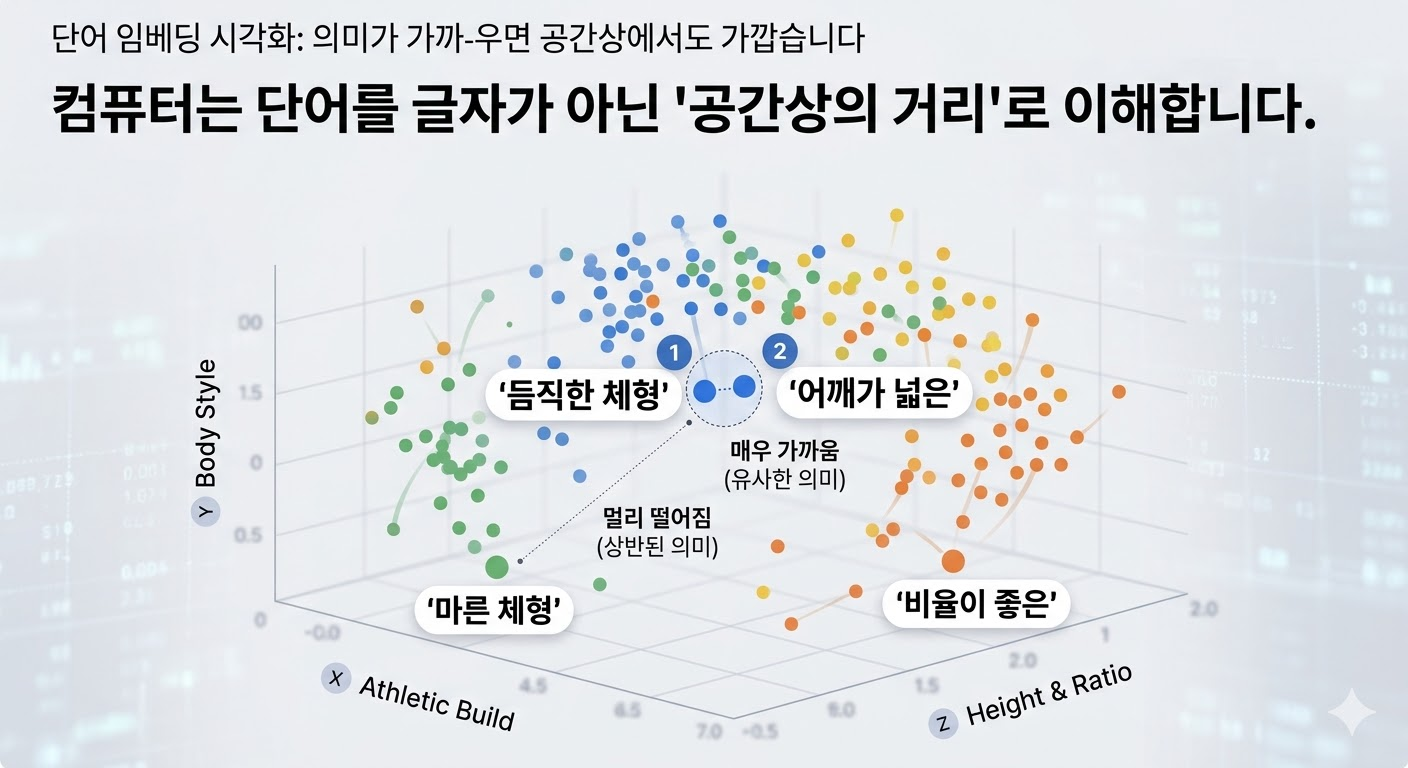
- 도서관 비유: 책을 가나다순으로 꽂는 게 아니라, 책의 내용과 분위기를 분석해 거대한 3D 지도 위에 점(좌표)을 찍어 배치하는 것과 같습니다.
- 효과: ‘듬직한’과 ‘어깨가 넓은’은 글자는 달라도 의미가 비슷하므로 지도상에서 아주 가까운 거리에 좌표가 찍힙니다. 컴퓨터는 이 거리를 계산하여 문맥을 이해합니다.
4. RAG의 핵심 동작 원리 (R - A - G)
이제 유저가 “어깨가 넓은데 편한 셔츠 찾아줘”라고 질문했을 때, 서버 내부에서 일어나는 일을 3단계로 쪼개보겠습니다.
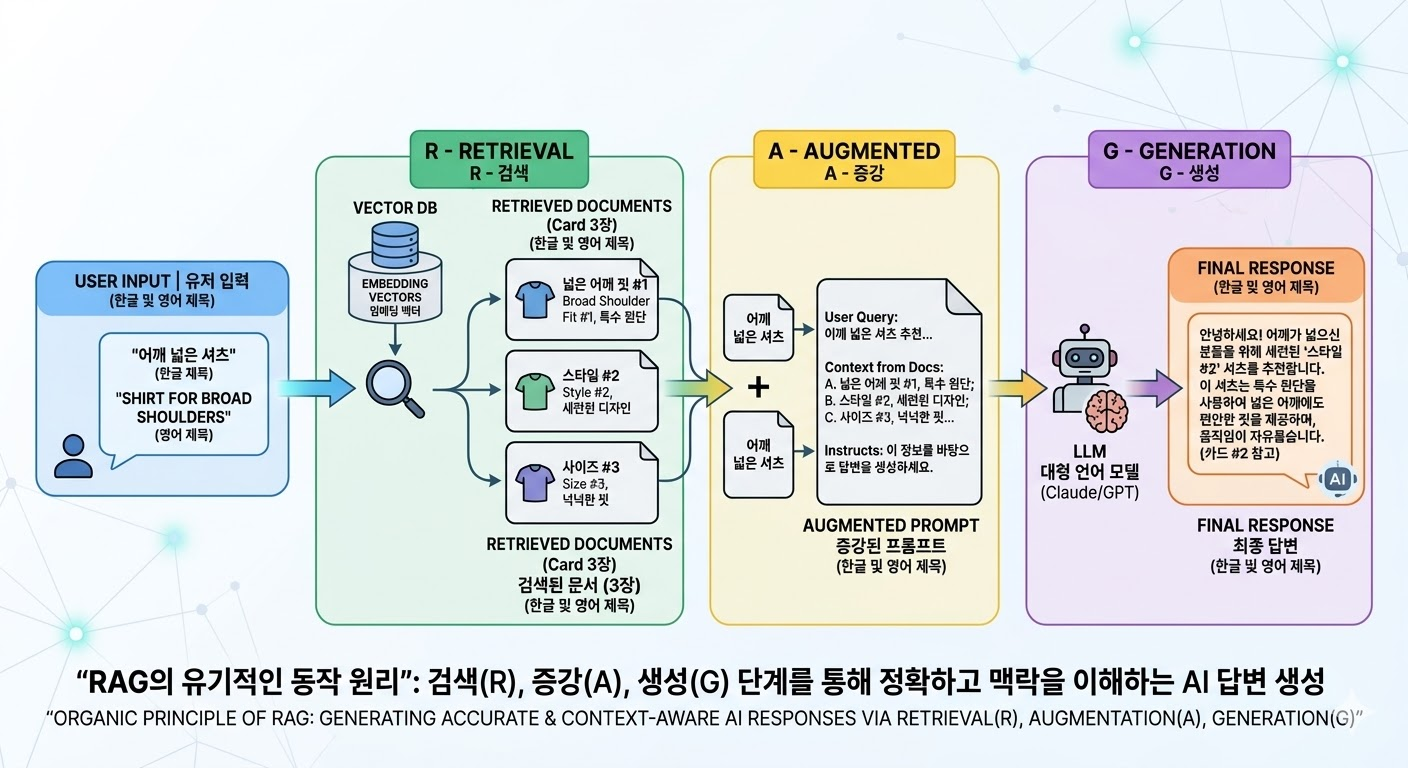
① Retrieval (검색): “지도에서 가장 가까운 책 찾아오기”
유저의 질문도 방금 배운 방식대로 좌표(벡터)로 변환됩니다. 그리고 우리가 미리 구축해 둔 Vector DB(우리의 경우 PostgreSQL의 pgvector)에서 유저의 질문 좌표와 가장 거리가 가까운 카드 데이터(책)들을 빛의 속도로 스캔해서 3장만 뽑아옵니다.
② Augmented (증강): “AI에게 참고서 몰래 펼쳐주기”
방금 DB에서 찾아온 3장의 카드 정보(모델 체형, 리뷰 등)를 AI 프롬프트에 몰래 끼워 넣습니다.
(시스템 내부 프롬프트: “유저가 어깨 넓은 체형의 셔츠를 찾네. 참고로 우리 DB에서 찾은 추천 후보는 A, B, C야. 특징은 이러이러해. 이 자료를 바탕으로(증강) 대답해 줘.”)
③ Generation (생성): “참고서를 읽고 맞춤형 답변 작성하기”
참고서를 전달받은 AI는 엉뚱한 거짓말(할루시네이션)을 하지 않고, 주어진 카드 정보 내에서 논리적인 답변을 작성합니다.
“찾아드린 A 모델도 유저님처럼 어깨가 넓은 편인데, 이 셔츠의 드롭 숄더 라인이 체형을 완벽하게 보완해 주어 핏이 예쁘게 떨어집니다!”
5. 굳이 우리가 직접 구축해야 하는 이유
“그냥 우리 DB 뽑아서 Custom GPTs에 올리고 API로 당겨 쓰면 안 돼?”라고 생각할 수 있습니다. 하지만 상용 서비스에서는 한계가 명확합니다.
| 구분 | ChatGPT GPTs / Gemini Gems | DEKK가 직접 구축하는 RAG 엔진 |
|---|---|---|
| 데이터 동기화 | 수동으로 파일을 계속 업데이트해야 함 | PostgreSQL과 실시간 연동 (새 카드가 등록되면 즉시 벡터화되어 반영) |
| 검색의 정교함 | 오픈AI가 주는 대로 써야 함 (블랙박스) | 하이브리드 검색! (예: DB에서 ‘상의’ 카테고리만 필터링한 뒤 ➔ 벡터 검색 수행) |
| 로직 결합 | AI의 텍스트 답변만 받을 수 있음 | 기존의 숫자 기반 체형 점수와 AI 유사도 점수를 믹스하여 앱 화면에 자유롭게 뿌려줄 수 있음 |
💡 결론
RAG 엔진은 전혀 낯선 기술이 아닙니다. “클로드에게 파일을 첨부해서 컨텍스트를 주입하던 그 과정을, 코드로 우아하게 자동화하는 작업” 입니다.